

Ursa Health Blog
Visit Ursa Health's blog to gain healthcare data analytics insights or to get to know us a little better. Read more ...
Categories
Algorithmic bias—what it is, who it impacts, what it causes, and how it is best overcome—is a topic of increasing interest in healthcare.
An algorithm is a set of rules that a computer follows in the course of automated problem-solving. Algorithms, in many ways, are like blood flowing through healthcare’s body, delivering information vital to its smooth, intelligent functioning. They are used to identify and correct nonstandard medical care that could result in poor outcomes, identify trends in diseases and groups of patients, predict whether a specific patient will deteriorate and how quickly so caregivers can be alerted—and the list goes on. Healthcare organizations can create their own algorithms but more frequently rely on IT vendors and their solutions to jump-start the problem-solving process.
Algorithmic bias is just one way these critical information building blocks can go awry. Although algorithms may be viewed as neutral and authoritative, they can, unfortunately, reflect, expose, and amplify inequities inherent in society, including social and economic biases based on age, gender, race, ethnicity, sexual orientation, gender identity, disability, and other characteristics. Data scientists are on the hunt for ways to eliminate this bias.
What is algorithmic bias?
Algorithmic bias refers to issues in model design, data, and sampling that lead to differential performance across subgroups. Three general types include:
- Outcome (label) bias, where the outcome variable has a different meaning across groups
- Feature bias, when there are group differences in the meaning of predictor variables
- Sampling bias, when minority groups are insufficiently represented in model development data
In 2019, Ziad Obermeyer and colleagues published a now-famous article in Science discussing evidence of racial bias in a widely used commercial algorithm that ultimately disadvantaged Black patients in the allocation of healthcare support resources. This algorithm, which was deployed nationwide, aimed to predict complex health needs of individual patients. It used healthcare cost as a proxy for health needs. Those at the 97% of risk threshold or greater were offered enrollment in a care management program to improve care of their complex health needs by providing additional resources.
However, Black patients needed to be sicker than White patients to qualify for the program: Black patients needed to have 4.8 chronic conditions while White patients only needed 3.8 chronic conditions. It is likely that Black patients had decreased access to the healthcare system, which prevented them from incurring the same costs as White patients with comparable health status. Hence, cost did not reflect health need, yet it was used to allocate resources, disadvantaging Black patients in the process.
In the design of predictive algorithms, the choice of outcome (or label) is crucial for aligning model estimates with program goals. While an outcome may appear reasonable in achieving the goal, it could introduce unintended bias. Thus, it is important to design algorithms with outcome labels closer to what may be considered the ground truth. In the above case, chronic conditions may have been a better representation of health need.
This past November at the American Medical Informatics Association (AMIA) Virtual Annual Symposium, Naveen Raja, D.O., of UCLA Health and Colin Beam, Ph.D., of Ursa Health presented their organizations’ work using a non-cost clinical predicted outcome to overcome racial bias. The goal is to better support population health programs at UCLA Health.
UCLA Health is an academic integrated healthcare delivery system with a presence in southern California that includes more than 200 ambulatory sites and 4 hospitals. The system serves between 600,000 and 700,000 patients annually, with approximately 400,000 patients in its primary care population.
UCLA Health built a risk stratification algorithm to identify primary care patients in need of care management and enroll them in a corresponding program, work that predates the Obermeyer paper. The outcome label had to meet three criteria:
- It must be clinically significant.
- It must predict an outcome that is preventable.
- The prediction should be made sufficiently in advance to allow time for intervention.
A non-cost clinical predicted outcome
The team constructed an outcome based on utilization of acute care rather than cost. Using data from the system’s primary care patients, the outcome predicts the risk of emergency room visits and preventable hospitalizations over the next 12 months. Data sources include UCLA Health’s electronic health record system, administrative claims, and a census-derived index based on patients’ addresses as a proxy for social determinants.
At the current decision threshold, the UCLA algorithm returns approximately 6,000 patients who are at risk of unplanned hospitalizations or emergency room visits. These patients are subdivided into highest, high, and rising risk categories. Rising risk means that these patients exceed the risk threshold; however, they have not yet had any hospitalizations or emergency room visits within the previous year. High and highest risk patients have had recent hospitalizations or emergency room visits. The highest risk group is the top 5% of risk.
These patients are impaneled by physician offices and assigned to a team of nurses, social workers, care coordinators, administrative staff, and physicians who work with these patients proactively to prevent hospitalizations and emergency room visits. This proactive care model has now been implemented in approximately 50 UCLA primary care practices across southern California.
Among the tested algorithms, gradient tree boosting displayed the best performance metrics, comparing quite favorably to results published in the population health literature for similar types of prediction models. A patient’s count of active conditions, also known as illness burden, was the most important predictor of the acute care outcome. Historical utilization features were also highly important, as well as various lab values, chronic conditions, and the Area Deprivation Index for the patient’s zip code.
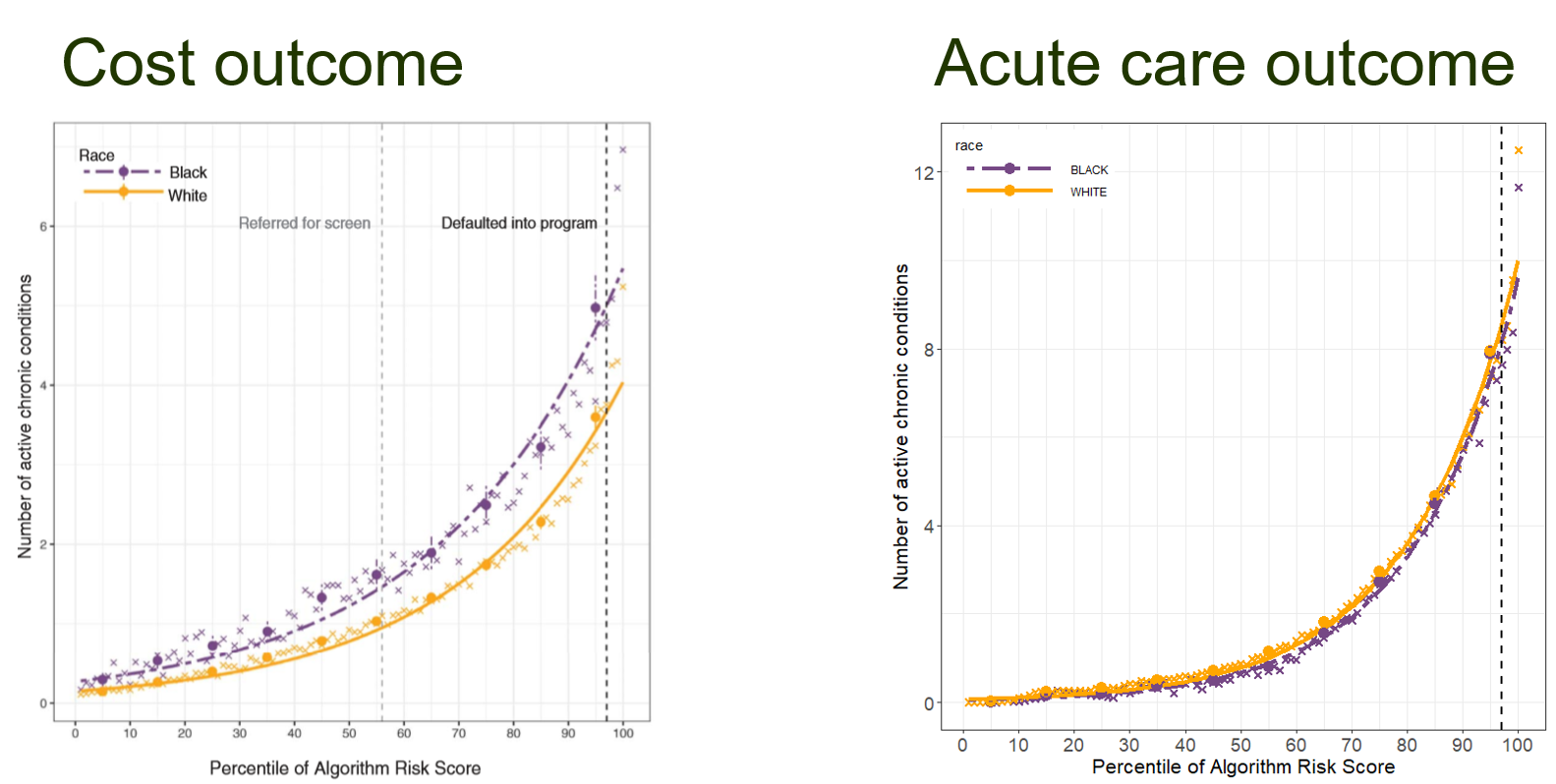
The key test of the acute care outcome is shown in the figure below. The general idea is that if there is no bias, patients assigned similar risk scores should have similar health status.
- The chart on the left is from the Obermeyer paper, which shows the results discussed above. At the 97th percentile risk score enrollment threshold, shown by the vertical dashed line, Black patients had an average of 26.3% more chronic illnesses than White patients with the same risk score (an average of 4.8 versus 3.8 active conditions).
- The chart on the right shows results from using the acute care outcome at UCLA Health. The differences between groups has decreased and also changed direction: At the 97th percentile score, Black patients now have an average of 7.3% fewer chronic illnesses than White patients at the same risk level (an average of 7.6 versus 8.2 active conditions).
Selecting the right outcome for predictive algorithms
What makes a good outcome label when constructing a risk score for population health? The general challenge is that the construct of health is not directly observable, so we need to pick a good proxy measure. Healthcare costs do reflect health need, with sicker patients incurring greater costs, but the problem is that they also reflect healthcare access, which is likely to correlate with race.
There are good reasons to believe that this type of issue will be less severe for acute care utilization. As Diehr and colleagues observe in their exploration of health care utilization, “The decision to have any use at all is most likely made by the person and so is related primarily to personal characteristics, whereas the cost per user may be more related to characteristics of the health care system.” In other words, seeking treatment, such as by visiting the emergency room, is primarily under the control of the patient, while the amount of treatment allocated is more at the discretion of the health system. For this reason, an acute care outcome is likely to be less susceptible to the problem of differential access across groups. And, with respect to the results presented above, the evidence appears to support this belief.
In light of these findings, we hope other healthcare systems explore this approach when they design predictive algorithms to identify high-risk patients from their primary care population.