

Ursa Health Blog
Visit Ursa Health's blog to gain healthcare data analytics insights or to get to know us a little better. Read more ...
Categories
For years, we’ve been reading headlines touting the power of artificial intelligence and machine learning algorithms, such as deep learning, to transform big data into actionable insights. Sounds impressive, right? But what does it all actually mean? Some argue these terms have strayed far from their original definitions, while others have criticized their misguided or cynical application.
To be sure, buzzwords and jargon can cause confusion or even be used to intentionally obfuscate. However, these terms can also facilitate more efficient communication by condensing a rich amount of specialized information.
Here, we attempt to unpack that specialized information by surveying and synthesizing expert views expressed in recent books, academic papers, blog posts, and podcasts. Although consensus on their meaning does not exist, these terms, the discussion that follows, and the links to additional reading scattered throughout should help those interested in learning more about the field share a common baseline of knowledge.
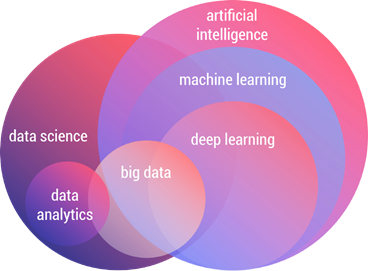
Figure 1. The taxonomy of artificial intelligence and data science (source: Orhan G. Yalçin).
The list
The following terms are those used most frequently when discussing advanced analytics:
Greater data science is everything that happens along the data journey, from when data first comes into existence until final results and decisions are achieved. Historically, this expansive definition was coined “data science” by the statistician Chikio Hayashi. But as the field has grown, the term has been partitioned to reflect the division of labor involved with the separate steps of data collection, design, analysis, and communication.
Data engineering builds systems that clean and integrate raw data from multiple sources and then organize the data into a framework or model that supports various analytics. Data engineers prepare the data that data scientists then use.
Data science is all the work that takes place after data engineers have had their go. This involves some additional cleaning and manipulation, but much of this work falls under the umbrella of “advanced analytics.”
Advanced analytics refers to methods applied, after data collection and preparation, to find and communicate meaning in the data. This includes prediction, inference, and visualization.
Data analytics is used as a general term to describe just about any task involving data. In the data science context, however, it refers to exploratory and descriptive analyses on curated data sets. It’s the work that “data analysts” perform. As Figure 1 implies, data analytics is data science that does not use the more complex methods.
Big data describes an amount of data that requires specialized computing resources and software to process in an acceptable amount of time.
Artificial intelligence (AI) began in the 1950s as the project of creating machines with human-like capacities for reasoning and problem solving. The original project focused on general intelligence, but the meaning has since expanded to encompass both narrow and general AI.
Artificial general intelligence (AGI) describes a theoretical AI that can learn and reason across distinct domains. AGI, also called “strong AI,” would have the ability to solve novel problems and to formulate and complete long-term projects.
Narrow AI is trained to accomplish a specific task. Also called “weak AI,” it constitutes all current applications of AI.
Machine learning (ML) is a type of AI that blends ideas from computer science, statistics, and other fields. ML algorithms use data to learn the best way to achieve an objective—usually accurate prediction. This contrasts with explicitly programming an algorithm to achieve some goal.
Data mining is the extraction of useful patterns from large data sets, which in turn may be used to make accurate predictions. ML provides techniques to assist with data mining.
Deep learning (DL) is an ML approach for constructing highly flexible models. DL is built with artificial neural networks, which are considered “deep” if they have multiple hidden layers.
Artificial neural networks are learning models inspired by biological neural networks. They are made up of nodes (neurons) and connections (edges) between nodes. A neural network includes an input layer that represents the external data, one or more hidden layers, and an output layer that stores the final results. Connection strengths between neurons (edge weights) are adjusted as learning from data proceeds.
Supervised learning describes learning tasks where predictor measurements are associated with outcome measurements. For example, various patient attributes, such as age and medical conditions, could be predictors for the outcome of future hospitalization. Most ML methods are designed for supervised learning problems.
Unsupervised learning finds groupings of observations that have a set of measurements but no associated response. Grouping health trajectories of lung cancer patients into several distinct types is an example of an unsupervised learning problem.
Reinforcement learning (RL) is a subfield of ML in which an agent learns by trial and error in an interactive environment. The agent chooses actions that result in different payoffs, and the goal is to maximize the total cumulative reward. RL algorithms have learned to defeat humans in games such as chess, Go, and poker.
Symbolic AI uses algorithms based on explicit rules that manipulate symbols. The symbols represent both abstract and concrete concepts, while the rules could come from something like algebra or logic. Symbolic AI is also known as traditional or “good old-fashioned AI” because it preceded the ML approach to AI.
Hybrid AI seeks to combine the rich prior knowledge of symbolic systems with ML’s ability to learn from data. It is also known as neuro-symbolic AI.
Intelligence augmentation (IA) is the use of computation and data to aid human intelligence.
Additional context on big data, ML, and AI
Now, to expand the discussion on several of the primary themes from the list.
Big data
We begin with the raw materials of analytics: the data. The above definition for big data implies that “bigness” is primarily a function of computing power rather than of the size or complexity of the data per se. As computers become more powerful, the size and complexity of data also increase, so yesterday’s big data is regular data today, and tomorrow’s data will be even bigger. Facebook’s user data is extremely big, storing over 300 petabytes in a massive data warehouse called the Hive. Various scientific research databases are also quite large, such as those found in genomics and astronomy.
Big data poses a variety of challenges and opportunities, and ML has supplied an attractive set of tools to address them. Highly flexible methods, such as deep learning, can give impressive results when applied to data sets with many observations. Google Translate, for example, is a deep learning model that has trained on over 25 billion sentences. Another type of big data is high-dimensional data, which has more predictors than observations. Genomic data is high-dimensional, as datasets can have hundreds of thousands of measurements on single nucleotide polymorphisms (SNPs), while the number of observations may only number in the hundreds. Penalized regression is an ML method that can be applied to high-dimensional data, while classical regression is inappropriate for these types of problems.
Machine learning
ML is defined, quite broadly, as a flexible, data-driven approach to AI. A more nuanced view places these methods on a machine learning spectrum according to how much of their structure is predetermined by humans versus how much is determined by properties of the data. One can also consider the trade-off between flexibility and interpretability (see Figure 2).
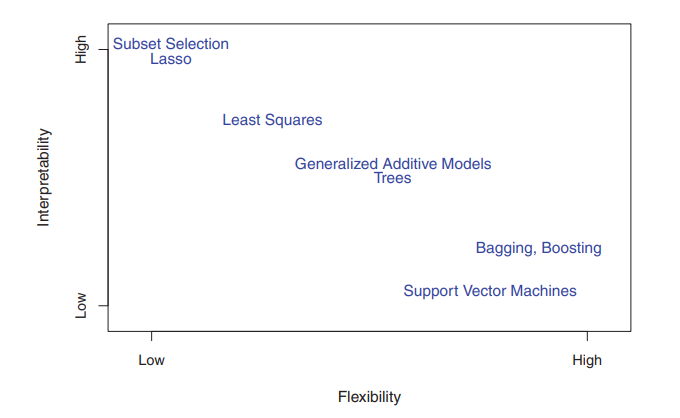
Figure 2. A representation of the tradeoff between flexibility and interpretability, using different statistical learning methods. In general, as the flexibility of a method increases, its interpretability decreases (source: Gareth James et al.).
Emphasis within ML has been on accurate prediction in contrast to inference, which focuses on describing and understanding the data-generating process. Black-box methods are perfectly acceptable when prediction accuracy is the chief concern; however, inference is needed if one wants to explain the predictions or characterize their uncertainty.
Artificial intelligence
When most people refer to AI today, they usually mean AI as it is implemented with ML. This is understandable, as ML has demonstrated a string of impressive successes, specifically for problems that have well-defined, narrow objectives and a huge number of learning opportunities. Yet some argue that AI is still far from achieving AGI. One path forward is by increasing the scale: using even more data and bigger models. Others believe that more effort should be devoted to improving data quality.
A third camp questions the ML-dominant approach to AI, as it claims that only so much can be learned from raw data. In support of this view are recent findings that increasing a model’s scale boosts performance for some tasks but has limited impact on others, such as for logical reasoning and common-sense tasks. Skeptics argue that ML is good at “curve fitting” or interpolating the data, but it struggles with novel problems that require abstract reasoning and a general understanding of the world. To achieve human-like inferences, they argue, the data must be interpreted against a rich backdrop of real-world understanding.
Recent work aspires to inject common sense into AI. The hybrid AI approach attempts to join ML’s powerful learning ability with symbolic AI’s capacity to represent general knowledge of objects, causality, space, and time. The hybrid approach remains controversial, with some prominent researchers arguing instead that DL should replace symbolic AI.
Proponents of hybrid systems seek to both expand the scope of AI and make its outputs more interpretable. Better interpretability is important for intelligence augmentation, which addresses how AI should inform human decision-making. Research is now being conducted on how to incorporate AI into clinical workflows—for example, to assist with cancer diagnoses.
Despite some successes, organizations have largely struggled to integrate AI tools into healthcare. Technology can guide actions, but high-stake decisions still require human oversight to avoid potentially catastrophic outcomes.
Getting on the same page
Analytics discussions can shape an organization’s strategy for years to come. Will that major AI initiative be a golden opportunity? Or is it more science fiction? A fruitful discussion starts with a shared understanding of key terms. A recommended best practice is to begin with explicit definitions in lieu of jargon at the outset of a discussion, especially when engaging with new topics or with new audiences. This will ensure a working consensus of meaning that is prerequisite for productive conversations.